
|
|
"L'acte de penser et l'objet de la pensée se confondent" Parménide Full Screen | Play Le contenu de ce wiki est Copyleft
|
Expérience de métrologie sémantique distribuée pour le web temps réel
Vers une Monnaie Complexe ? OlivierAuber 2009. L'appellation "web temps réel" recouvre un ensemble de pratiques émergentes rendues possibles grâce à des plates formes propriétaires de type Twitter et des réseaux distribués fondés sur des logiciels libres de type Identica. Les micro-messages échangés sur le web temps réel s'imposent depuis seulement deux ans comme de nouveaux vecteurs d'information, de confiance et de recommandations entre usagers du réseau. Cette nouvelle forme du web apparaît comme une nouvelle frontière dans le domaine du "search" de l'information "brûlante" comme en témoignent les récents accords entre Twitter d'une part, et les moteurs de recherche Google et Bing d'autre part. Le présent projet vise à surmonter plusieurs lacunes du web temps réel, à savoir notamment sa relative incapacité à consolider le flux des messages sous une forme structurée exploitable en temps réel et a posteriori, ceci à toutes les échelles, depuis celle de l'utilisateur avec son cercle de relations, jusqu'à celle globale d'une certaine thématique faisant l'objet d'échanges dans toutes les langues possibles. Contrairement aux systèmes de traitements et des visualisation de données a posteriori (data mining), notre projet s'appuie sur un traitement a priori par l'énonciateur même des expressions composant ses messages, avec l'assistance d'un thésaurus évolutif de tags fondé sur le langage IEML en cours de mise au point par Pierre Lévy à l'Université d'Ottawa. Une maquette fonctionnelle a déjà été réalisée en ce sens avec la complicité de plusieurs utilisateurs de Twitter et d'Identica. Elle a montré que cette démarche active de pré-traitement par les utilisateurs est non seulement possible, mais que ceux-ci en perçoivent les bénéfices, notamment pour donner une image plus tangible aux liens qui les réunissent et aux fruits de leurs échanges. Nous entrevoyons à travers cette première expérience que cela pourrait conduire à de nouvelles pratiques culturelles, comme par exemple le "CV performatif" réunissant les compétences tangibles des personnes, ceci s'opposant à l'habituel CV déclaratif... Nous proposons de poursuivre cette exploration en mettant au point, d'une part des outils de pré-traitements IEML semi-automatiques qui simplifieront la tâche des utilisateurs, d'autre part des outils temps réel d'analyse de flux et de visualisation qui permettront aux utilisateurs d'obtenir une synthèse directe des échanges en train de s'effectuer. La mise au point et l'expérimentation de ces outils en version Bêta s'effectuera avec un groupe d'utilisateurs volontaires. Au final, la perspective dégagée par ce projet est de proposer une approche sémantique d'un web temps réel distribué pouvant être agrégé en n'importe quel point du réseau. Livrables :
Licences : ces logiciels seront publiés sous licence GPL Partenaires potentiels:
Historique de l'idée Cette idée a été émise lors d'échanges sur Twitter en mars 2009: http://twitter.com/OlivierAuber/status/1376626256 give 1 #exploracoeur @plevy for #*w.a.-d.-' (expérimenter) #TwitBank http://tinyurl.com/c7ylzb et faire le lien avec l'arbre via #IEML Maquette fonctionnelle Une série d'échanges de ce type entre plusieurs personnes sur le réseau Identica et la plate forme Twitter au printemps 2009 a conduit à ces visualisations en utilisant les possibilités IEML, la plate forme TwitBank d'analyse de flux et de visualisation (graphe), et la plateforme Ligamen? de visualisation (arbre des compétences): 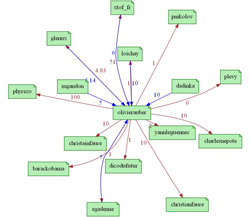  Liens Liens vers des projets proches
Discussion OlivierAuber > PierreLevy Bonjour pierre, Je t'assure que jusqu'à maintenant, je n'avais vu autour de moi, malgré mes tentatives d'explication, que des gens qui ne comprenaient pas ieml, et d'un seul coup, mes petits bricolages ont produit des déclics! Je me suis plu à imaginer un client léger pour twitter (ou plutot pour Laconica/identica) qui permettrait lorsque l'on formule un échange avec une syntaxe de type : @jean 10 @marcel pour ta super traduction (Jean donne 10 unité monétaires à Marcel pour sa traduction) .. de détecter le mot "traduction" et de proposer à la manière d'un correcteur orthographique divers équivalents ieml qui pourraient correspondre au sens que Jean veut formuler. Après validation, le correcteur ré-écrirait le message en encapsulant le ou les tags ieml dans le message de manière visible ou invisible de la part des utilisateurs. Bien entendu, le tag ieml entré par jean viendrait grossir la compétence "traduction" de Marcel compilée et visualisé sur une plateforme ou une autre. Il me parait évident que quelque chose comme cela figure dans ta feuille de route. Ma question est quand? Si cet horizon est encore lointain par manque de moyen et de temps de ta part, il me parait possible de le rapprocher cet horizon en s'appuyant sur la communauté des développeurs et des utilisateurs pilotes rassemblés autour d'Identica, de la TwitBank et d'Apprendre 2.0 qui sont particulièrement actifs et souples. Ton manque de moyen et de temps que tu me signalais il y a peu pourrait être compensé avantageusement de cette manière. Mettre de l'ieml dans le microblogging implique de travailler avec les développeurs de ces systèmes. Ce qui me parait difficile avec ceux de Twitter me parait plus facile avec ceux de Laconica. Voilà, cette idée est peut-être très naïve. Tout celà est peut-être déjà en route avec Laconica ou d'autres.? J'aimerais en savoir plus PierreLevy > OlivierAuber Samuel Szoniecki (samszoAT free DOT fr) a DEJA développé un outil qui ressemble beaucoup à celui que tu imagines, mais pour traduction semi-automatique des tags delicious. Contacte-le. Pour Twitter, ma petite équipe prévoit qqch de beaucoup plus ambitieux (moteur de recherche nouveau genre), qui sera basé sur la prochaine version du dictionnaire incluant... (a) la nouvelle syntaxe conforme au parser IEML, (b) la formalisation du réseau sémantique entre les termes IEML de la base de donnée XML sous-jacente au dictionnaire et (c) une foule de nouveaux termes. Honnêtement, je ne penses pas que ça vaille le coup de programmer une appli AVANT d'avoir cette nouvelle version, parce que tout serait à refaire après. C'est surtout (a) et (b) qui prennent du temps, parce qu'il faut un parser pour le langage (très élaboré, incluant des opérations de génération automatiques d'arbres d'expressions IEML) de définition des relations + un programme qui tisse les liens automatiquement à partir de ce langage... Je vais poster dans une dizaine de jours un nouvel article expliquant VRAIMENT (pour la première fois) IEML... PierreLevy > OlivierAuber OK bricole, mais sache que ce n'est encore que bricolage OlivierAuber > PierreLevy Merci pour le contact de Samuel. Je vais le contacter. J'avoue que je ne comprends pas bien les intentions du moteur de recherche tel que tu le décris pour le moment. S'il s'agit d'exploiter la base des twitts telle qu'elle est actuellement structurée par le graphe social et les hashtags, quel peut être l'apport d'IEML? Franchement quelque chose m'échappe. S'il s'agit de proposer un nouveau type de structuration de Twitter, il faudra intervenir sur Twitter lui même, ce qui paraît difficile. D'où l'idée de se rapprocher de Laconica qui est sans doute plus souple et qui présente l'avantage d'être opensource. J'espère que j'y verrai plus clair avec ton article. Vu de ma fenêtre, l'intérêt d'IEML est d'être une passerelle potentielle en le langage naturel et la machine, qui peut en retour donner toutes sortes de visualisations à l'homme - non pas le "user" ni le "customer" hein;-) - des structures sémantiques qu'il forme et dans lesquelles il évolue. Je ne vois pas comment cette passerelle peut être automatisée pour le langage courant. Et à supposer que cela soit possible, je me demande si cela ne serait pas contre productif en terme d'appropriation de la démarche, voire si cela ne provoquerait pas des mouvements de rejet face à ce qui pourrait être vécu légitimement comme un système à déposséder les hommes de leurs propres mots. Vu de ma fenêtre toujours, IEML pourrait être une sorte d'extension du langage humain qui démultiplierait ses possibilités d'expression et d'interaction par l'intermédiaire des visualisations qu'il permettrait. Pour que le bénéfice social et psychologique de ce langage soit avéré - en gros qu'un sens émerge de la boucle de rétroaction - il me semble qu'il faut qu'il y ait quelque part une démarche volontaire pour pratiquer cette langue. C'est pourquoi l'idée sans soute modeste d'employerr IEML pour décrire volontairement l'objet des échanges me paraît pertinente. Lorsque dans l'exemple cité dans mon précédent mail (@jean 10 @marcel pour ta super traduction) Jean crédite crédite Marcel non seulement d'une valeur quantitative éventuelle en "hashtagmoney" mais aussi de la compétence de "traduire", compétence que Marcel pourra faire valoir par la suite auprès d'autres par le biais des arbres de compétences par exemple. Le bénéfice social de cet échange semble évident pour Jean et pour Marcel. A aucun moment, ils n'ont été dépossédés de leurs mots, de leurs intentions réciproque et de leurs désirs, ceci d'autant plus que ces échanges ne transitent pas par un opérateur intermédiaire en position de monopole. Voilà, cette idée me donne envie de bricoler, sans y passer trop de temps une petite maquette. Rien ne sera automatisé. Avec quelques complices, nous ne ferons que piocher dans le dictionnaire IEML au fil de quelques échanges. Cela n'a pas d'autre vocation que de réfléchir en agissant et d'aider peut-être à clarifier certains points dans le domaine explosif et chaotique des monnaies virtuelles. Comme je n'ai pas malheureusement pas de moyens ni de temps à consacrer au développement d'un client léger permettant d'aller plus, cela s'arrêtra là, à moins que l'exprérience en inspire d'autres, qui sait? J'attends ton article avec impatience pour en savoir plus sur cette histoire de moteur. A suivre... sur Twitter avec le hashtag #IEML
Il n'y a pas de commentaire sur cette page.
[Afficher commentaires/formulaire]
|